Autograd,自动微分,是整个pytorch框架的核心功能。我一直是只了解原理,但却不知框架是如何实现的,这次看到一个非常好的教程,所以打算把理解总结一下。
用pytorch实现微分计算的基本流程是:
- 定义需要进行计算的tensor。其中一部分的tensor只是纯粹用来计算,并不需要更新,比如说输入的数据;而另一部分的tensor是参数,它们会参与到计算中,但同时我们也想对其进行更新。对于需要更新的参数,设置requires_grad = True来要求自动微分框架计算grad。
- 利用定义好的tensor,对其进行forward(前向)计算,比如算loss。这个过程中,计算的结果会保存在tensor的data属性中。
- 在前向计算的过程中,自动微分框架会隐式地构建一张backward graph。这张图结构取决于各个tensor的requires_grad,is_leaf(叶节点),以及相应的加减乘数函数操作。
- 把前向输入的data代入backward graph,得到每个需要grad的tensor的grad。
- 根据梯度,调整当前参数值。
以上的流程中,可以看出Tensor的核心属性就5个:data, grad, grad_fn, is_leaf, requires_grad。
简单例子
(抄自 Elliot Waite)
从例子开始讲具体的流程,假设现在有a,b两个tensor,然后把它们乘起来得到c,如下:
import torch
a = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(3.0, requires_grad=False)
c = a * b
执行了以上的代码之后,实际过程如下:
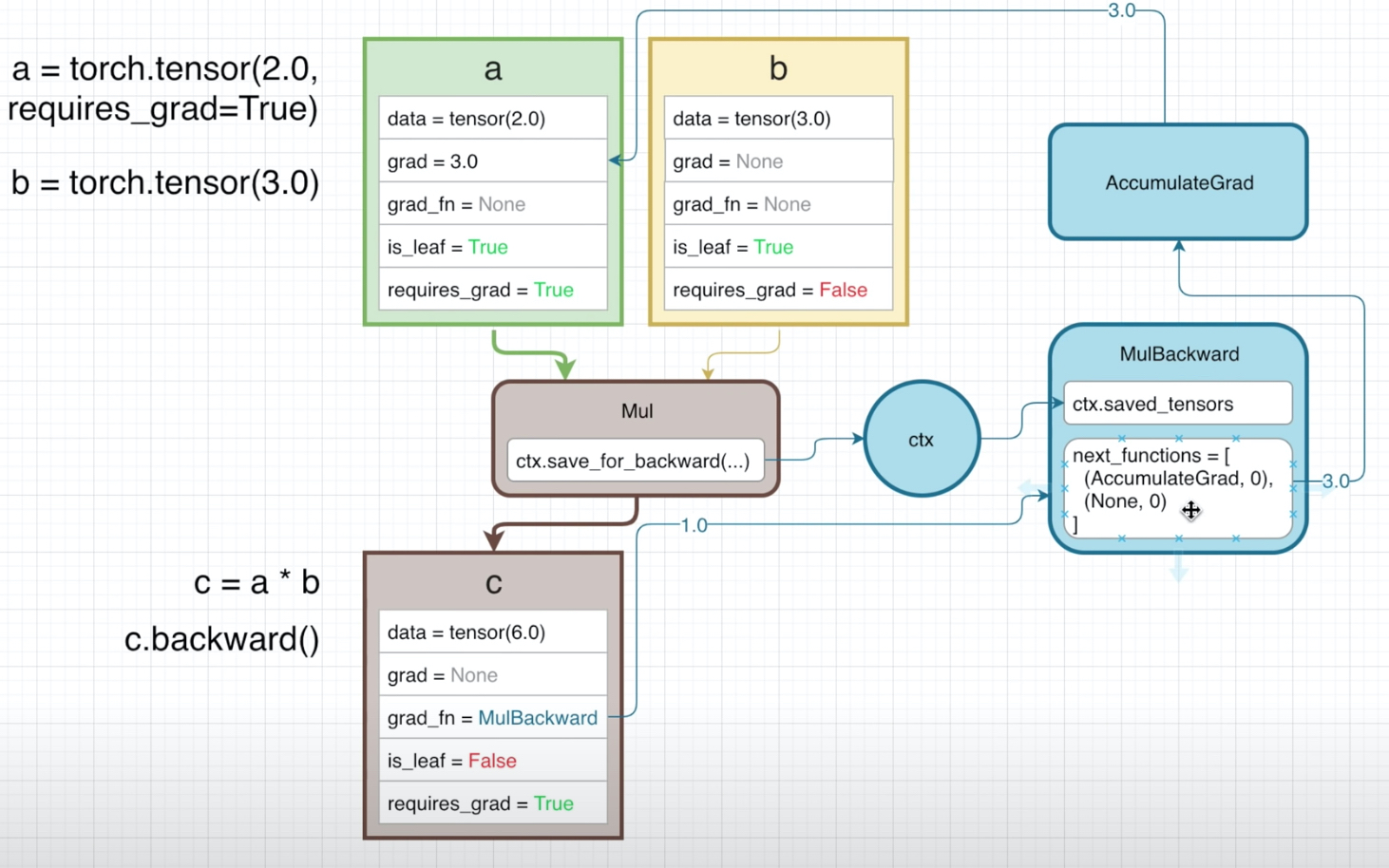
-
这里绿色的框表示叶节点并且requires_grad = True,而黄色的框表示叶节点但是requires_grad=False,褐色的框表示非叶节点的中间节点。这三种颜色是在forward graph里,而蓝色的框表示的是backward graph。
-
由于设置a是需要梯度的,所以b和a相乘得到的变量c,也自动变成需要梯度了。
-
Mul先会去得到一个context variable,然后把输入到Mul的所有tensors(这里是a和b)的data,存储到这个ctx里面;这里用ctx.saved_tensors来表示。这里我们用了相乘,如果是加法操作的话,我们就不需要这个ctx.saved_tensors了,直接传梯度1.0上去就行。
-
此外,因为有两个input tensors,所以MulBackward会有一个next_functions来指向后续的两个函数(来进一步传导梯度)。在这里,由于b不需要梯度,那么就可以设置为None,也就把梯度传导断了。a是leaf node,所以直接指向AccumulateGrad,不需要再指向其他的后向图里的xxxBackward了。
-
Tensor c会设置grad_fn的reference来指向backward graph里的MulBackward节点。
-
当执行c.backward()时候,梯度就会从c的grad_fn开始(初始化为1)传导到MulBackward。None的部分直接跳过,只需要看AccumulateGrad就行,用AccumulateGrad来更新leaf node, a, 的梯度。这里(Accumulate Grad, 0) 指向node a,而这个“MulBackward”对于a的梯度,就是另外的所有输入tensor的乘积(这里只有b,也就是3)。
稍微复杂一点的例子
import torch
a = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(3.0, requires_grad=True)
c = a * b
d = torch.tensor(4.0, requires_grad=True)
e = c * d
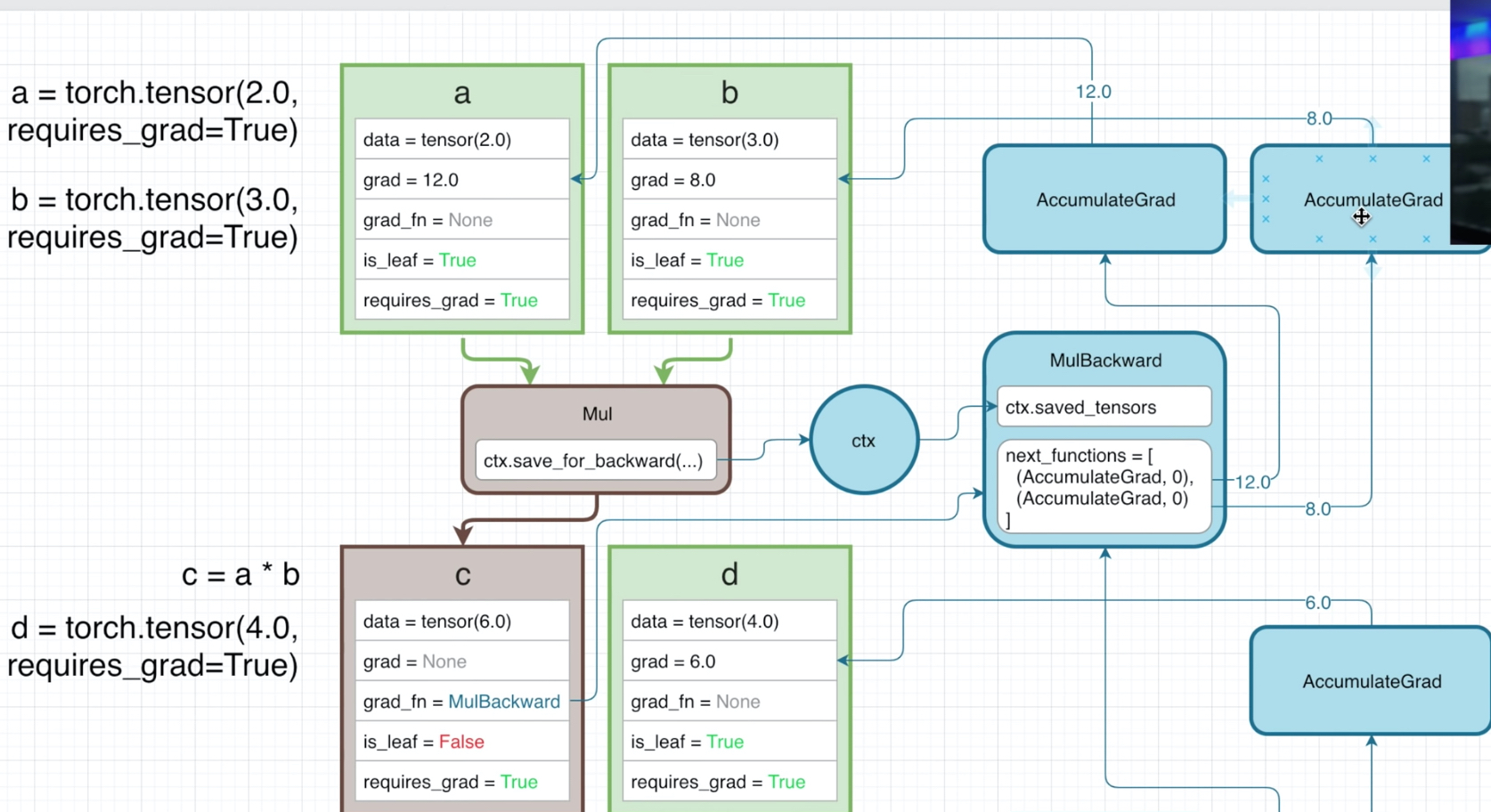
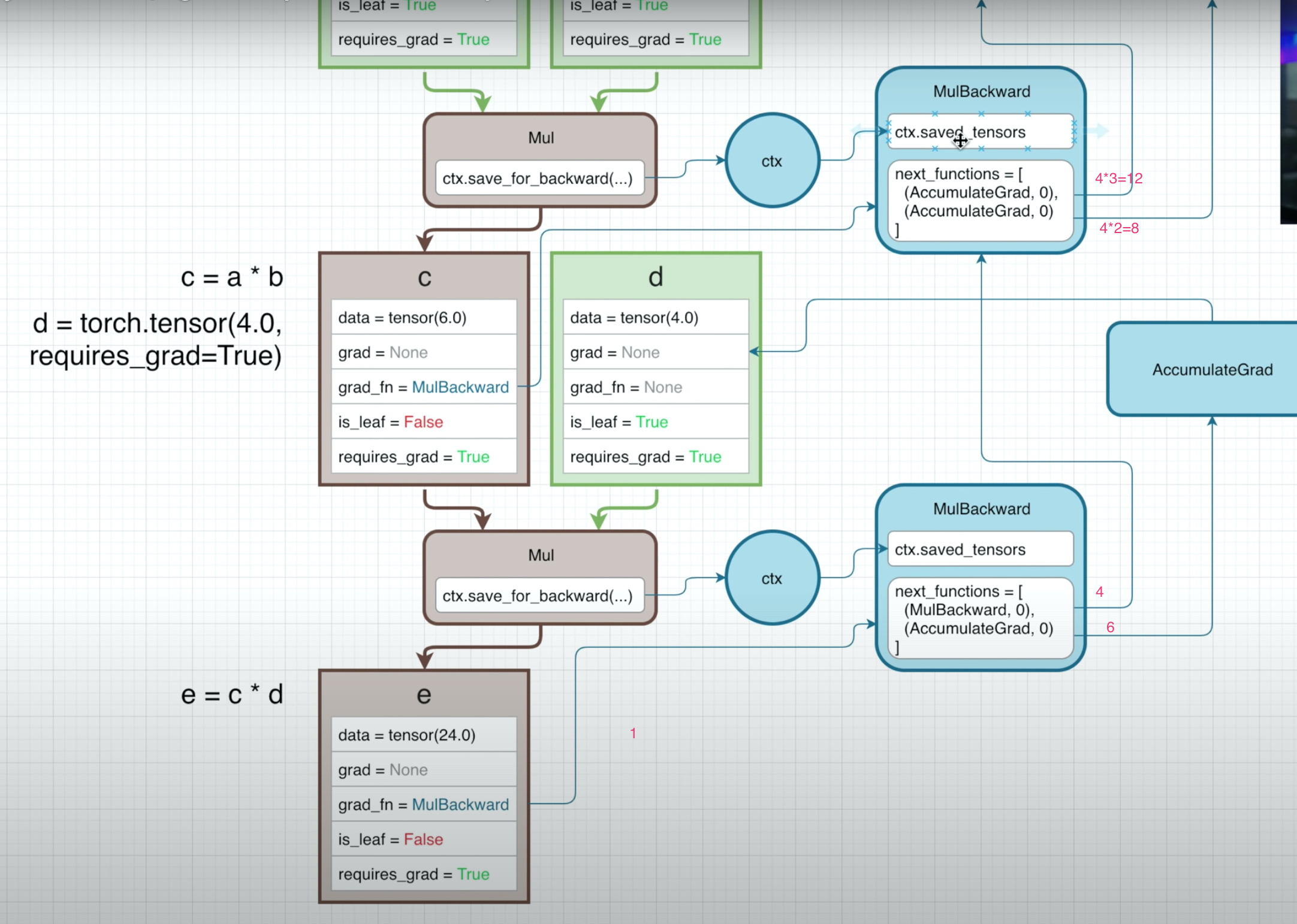
这里最关键的一点:c和d相乘构造的MulBackward,其中第一个next_function是指向c的grad_fn,也就是上面简单例子里讨论的那个MulBackward。
因为c不是leaf node,所以我们并不感兴趣它的grad。当然我们强行得到它的梯度也是可以的:
c.retain_grad()
Unbind()
在前面例子里,你可能会好奇next_functions的list里面,为什么tuple的第二个元素,都是0 ?这个0是什么?其实这个是index,用来表明这个计算的第index个输出。(前面的例子不是加就是乘,所有的输出都是只有1个,所以都是index 0)。下面这个例子,很好地说明了它的用途:
a = torch.tensor([2.0,3.0,4.0], requires_grad=True)
b,c,d = a.unbind()
e = b * c * d
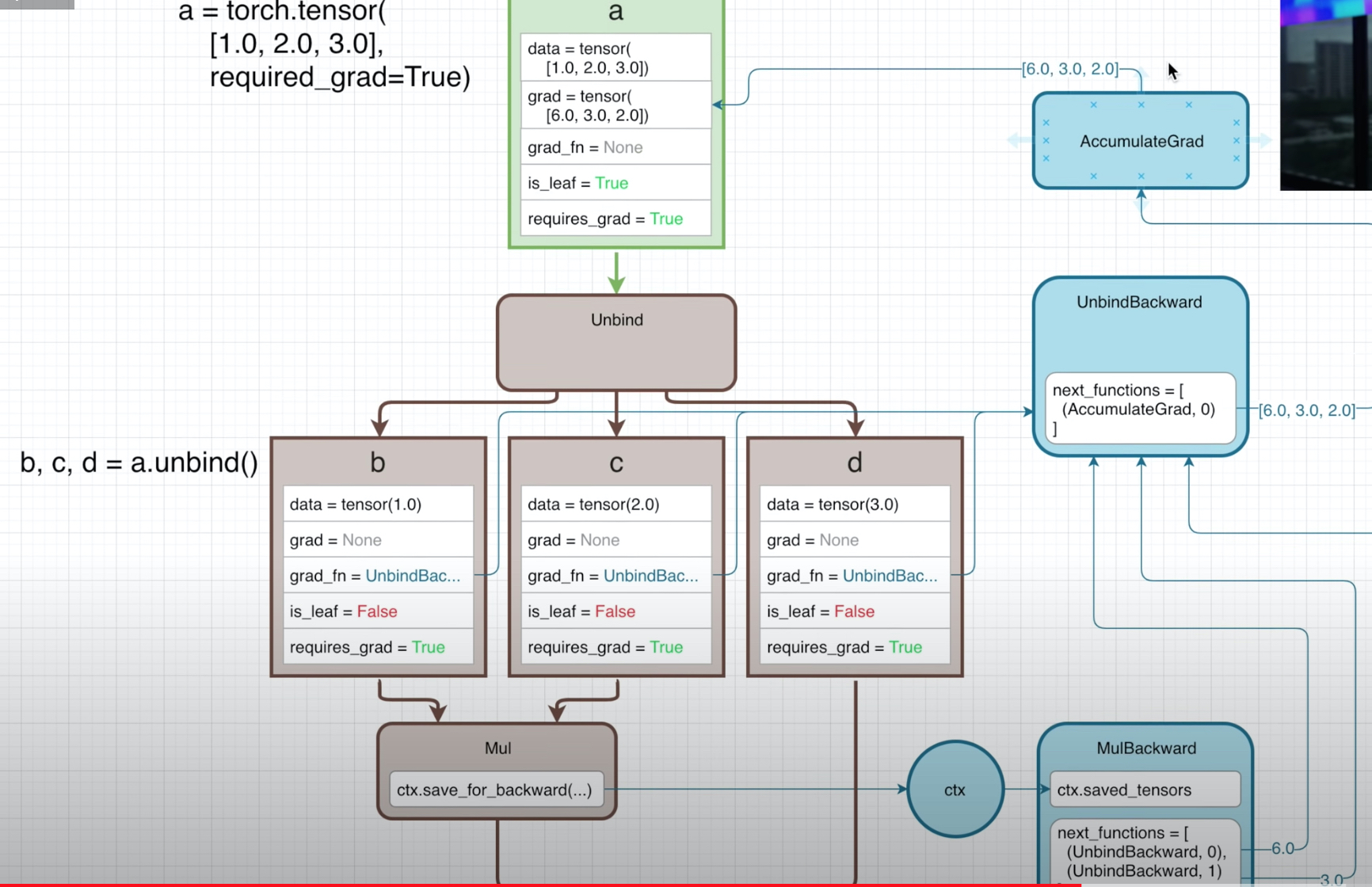
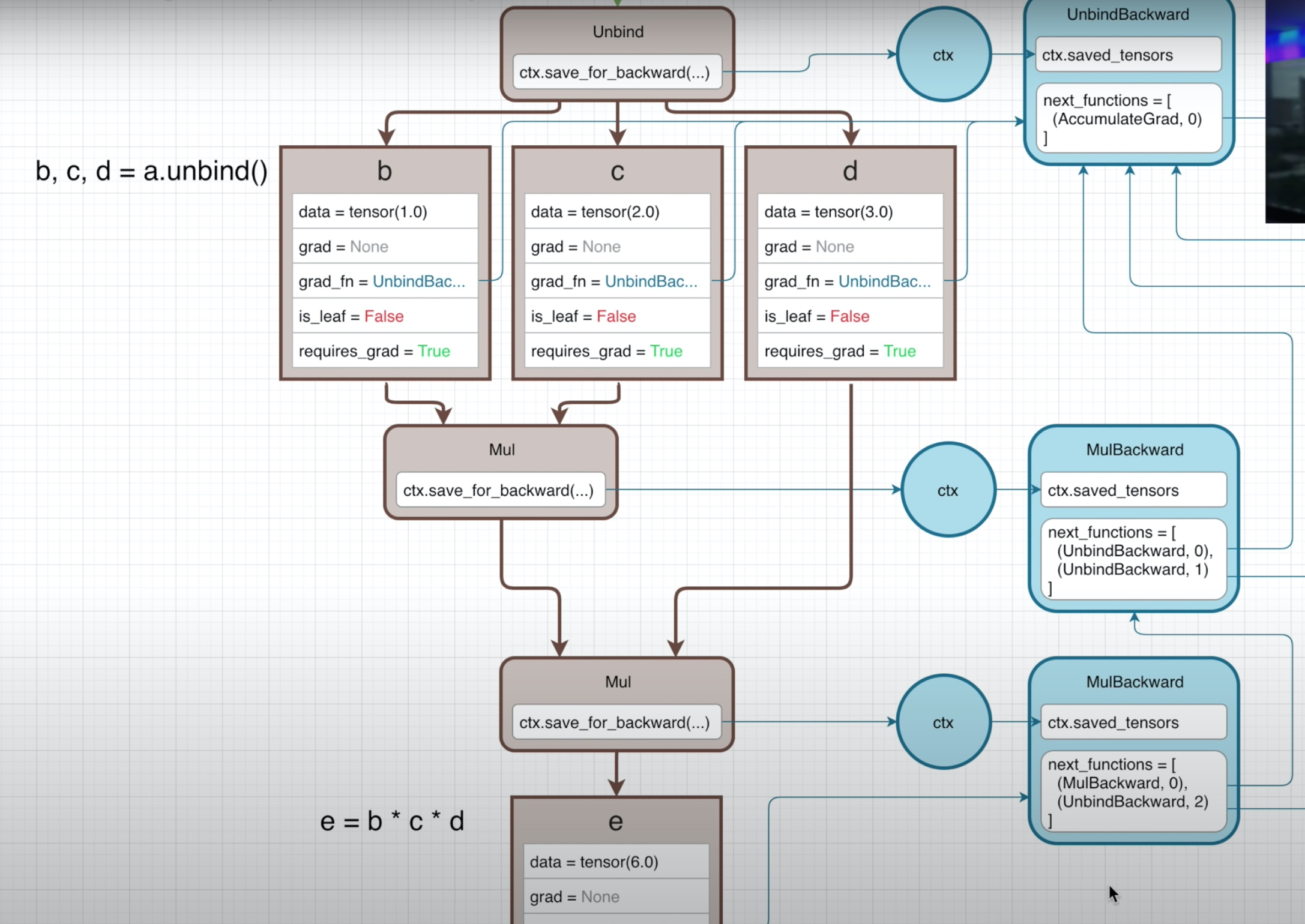
这里我们可以清楚看到这两个MulBackward,里面不同的index对应了unbind操作的不同输出。最后会看到,整个dim-3 tensor的grad,出来的也是dim-3。这个操作,对于求一个tensor沿着一个dim的和,然后求梯度就很方便。